Working on k8s clusters always gives me the feeling it’s almost alive. Hundreds of processes constantly carrying on their responsibilities, just as they would in a living organ.
You probably know that your cluster abilities can be extended by installing custom operators. Where are core processes being taken care of? Well, they are managed by the hardest-working control-plane component: kube-controller-manager.
Every reconcile loop, about 30 operators are handling core functionality like getting pods up and down, updating service endpoints, starting jobs, setting status fields to k8s objects and watching for related changes.
Today we are poking into one of the most thought-through, famous and yet mysterious operator - the DeploymentController.
As they tell you on k8s 101, a deployment is the common way to manage one or more pods on the cluster. But is it?
In terms of code, in order to do so, you have to implement a some pod management functionality, known as PodControlInterface. View source
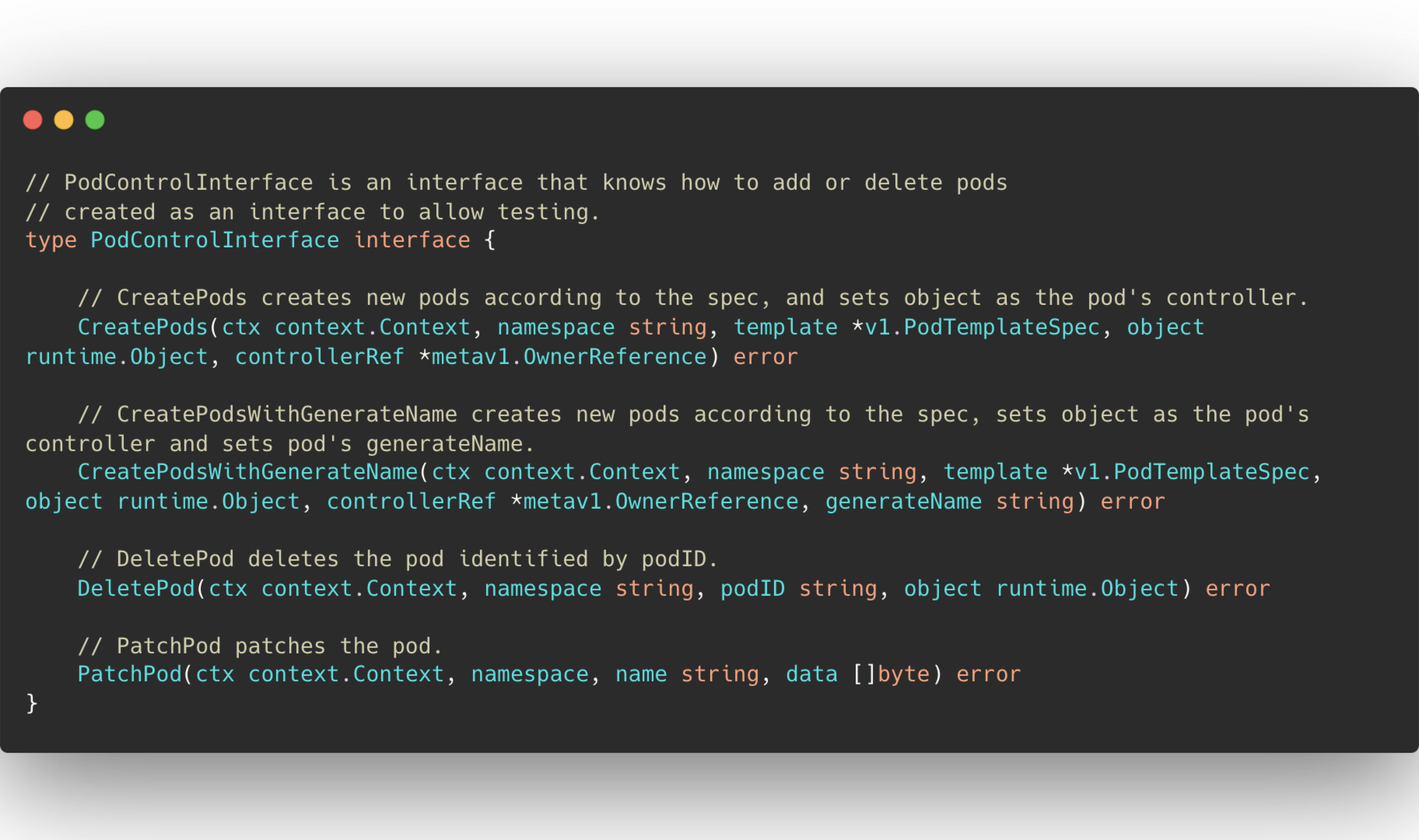
4 operators implement this interface- DaemonSet, StatefulSet, Job and replicaSet. Deployment is not one of them. Instead it is built on top of a replicaSet. But why?
Unlike DaemonSet or StatefulSet, Deployment is usually allowed to deviate a bit from its configured amount of pods, on the other hand it allows you to change configuration on the fly, unlike Job, which its podSpec is strictly immutable once applied.
Those features create deployment greatest flex - updates.
The holy bible of devops, Site Reliability Engineering by google architects, dedicates a full chapter to the value of automation, which shines on system updates. Deployment gives you a rich set of configurations,to customize the most safe, automated update process. Let’s take a look:
Update Types
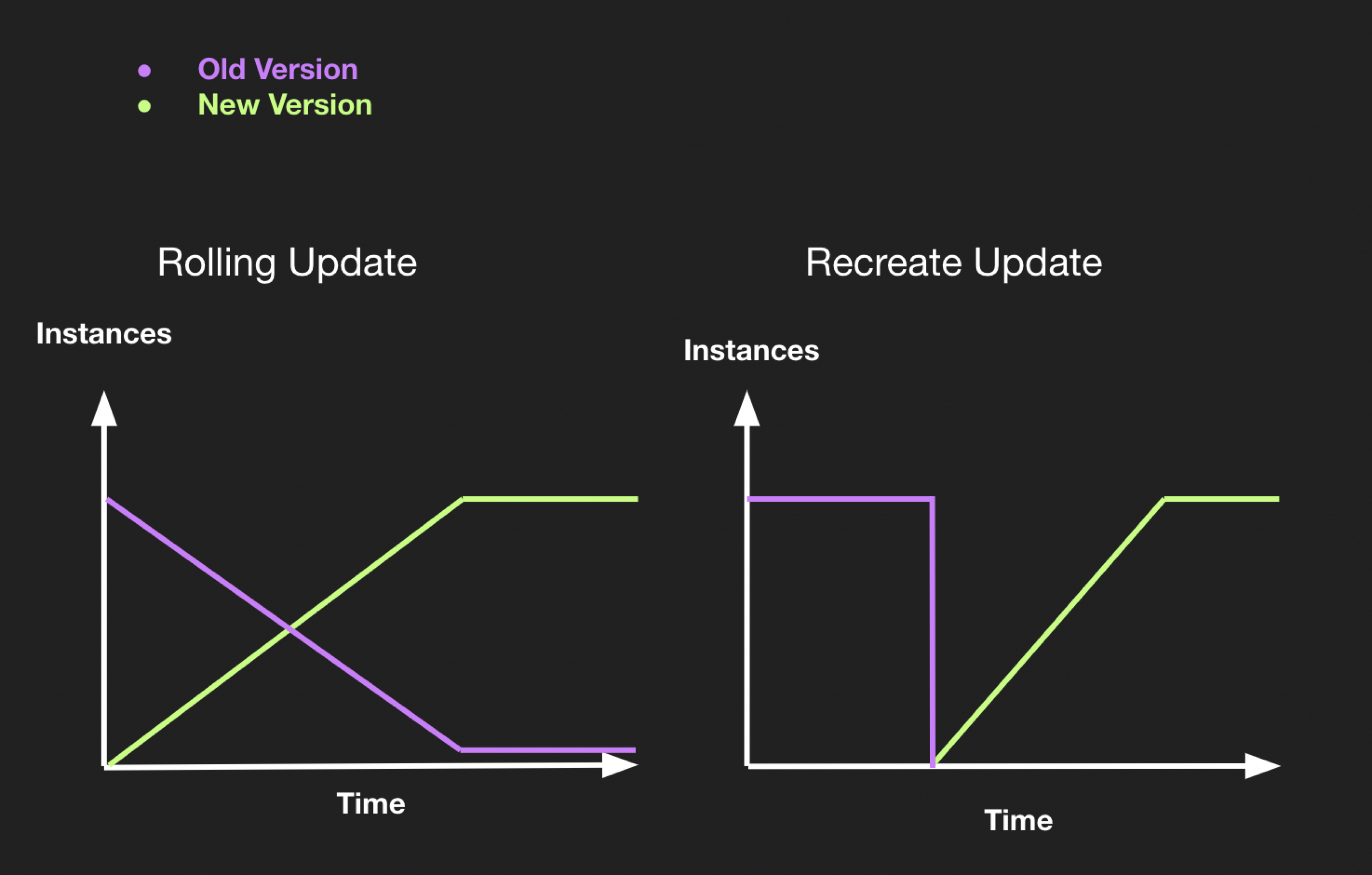 Unlike recreate update (delete everything and then deploy a new version), During a rolling update pods are carefully terminated and created one by one, to ensure maximum availability.
Unlike recreate update (delete everything and then deploy a new version), During a rolling update pods are carefully terminated and created one by one, to ensure maximum availability.
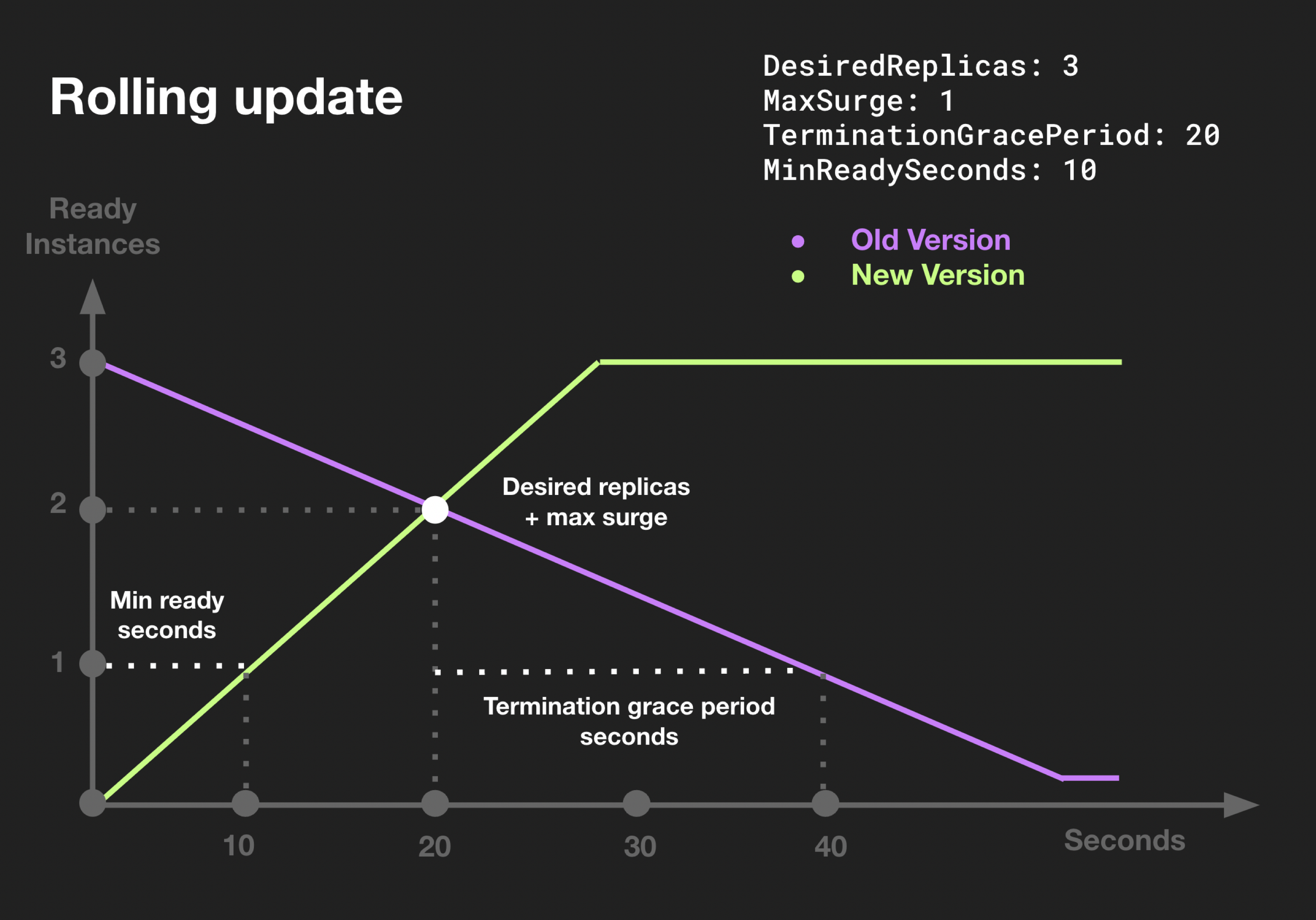
As you will see, you have full control on the progress. Let’s say you configured replicas to be 3. While an update is being rolled, at some point you will have 4 pods available (replicas + maxSurge). Higher maxSurge means updates can roll faster (more new pods can be started at once). Once a new pod is considered ready (alive for at least the amount of MinReadySeconds), an old pod will be terminated within (at least) 20 seconds (TerminationGracePeriod).
(You can configure an optional timeout via progressDeadlineSeconds - we will get back to this.)
The HOW Part
Since deployment is not managing pods directly, but replicaSets, you can imagine that during an update the deployment scales down the old replicaSet, and scales up the new replicaSet.
If you go to a deployment namespace and run kubectl get replicaSet you will see a bunch of zero-scaled replicaSets aging in peace ![]()
![]() (the exact amount equals
(the exact amount equals deployment.spec.revisionHistoryLimit, which is 10 by default). They are kept there so you can rollback to a point in time if you are not happy with the new version.
How deploymentController tells which pod belongs to each replica? With you, beloved kubegeeks, I am glad to share my findings.
As you know, a pod name usually looks like this:
<deployment name>-<some hash>-<another nonsense hash>
Well unlike the last hash string (which is indeed a total random nonsense), the middle hash is super meaningful. In-fact this is a hash representation of the entire pod spec. replicaSets names are derived from this hash (<deploymentName>-<podSpecHash>) meaning a new replicaSet only ever created when the pod spec is altered. A replicaSet also uses the hash as its labelSelector, and has its pods labeled accordingly.
For a deployment to tell what is its latest replicaSet, there is a special revision annotation to both the deployment and its replicaSets. The deployment annotation increments every update (to match the new replicaSet):
 The reconcile loop looks something like this:
The reconcile loop looks something like this:
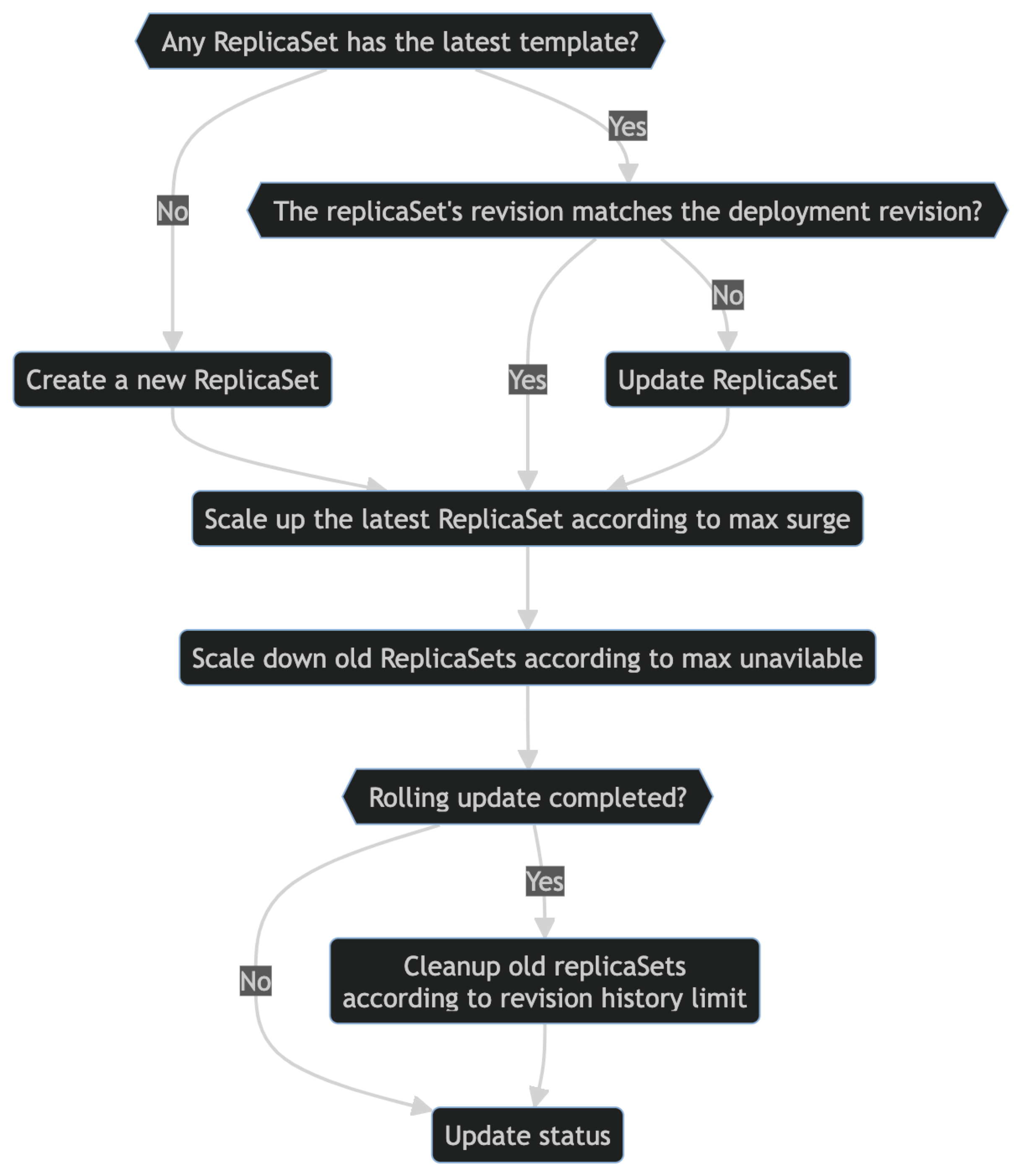
What does future holds for deployment controller?
Interesting things for sure. Here are some features worth waiting for:
- As promised, at some point we will be able to allow an automatic rollback if the rolling update fails to complete within the
progressDeadlineSeconds.
- Scale to 0 - The core functionality of deploymentController does not allow you to set
.replicas: 0, which is unfortunate. Meantime, you will need the help of external tools like Keda.sh. - More update types - An interesting issue discussed since 2020, suggesting to add a third update type adhering to the BlueGreen release mechanism,
 if you like it as well!
if you like it as well!
